 登录
登录
 2025.08.21
2025.08.21 4085
4085
在过去六个月里,世界在AI智能体(Agentic AI)领域的发展速度可谓从零加速至每小时60英里...
如果你最近没有关注这个领域,从思维模型(mental model)的角度来看,你可能已经落后了。在这篇文章中,我将逐步讲解,从基础开始,逐步构建。所以,如果你像我一样是一名工程师,过去一年没有深入研究过这个领域,那么你可以快速上手,而不必费力钻研大量细节才能重新构建整体框架。
高层架构
LLM (大语言模型)
这些是过去几年我们在大多数常见LLM应用(如ChatGPT网页应用、Claude桌面应用、VS Code Copilot扩展)中处理的标准组件:
- LLM
- 使用LLM的应用程序(基于浏览器或原生应用)
- LLM API(用于作为服务运行的LLM)

这种方式很好,很简单,并且看起来几乎就像任何前端/后端应用程序一样。
智能体 (Agents)
基本组件:应用程序、LLM 和 LLM API 并没有改变,但应用程序本身已经进化了。它不再只是一个传递式的聊天界面,而是变得更加复杂和自主。
可以把它想象成一个在循环中运行的应用,拥有它之前所做操作(提示及其响应)的一些记忆(上下文),并通过LLM API反复调用LLM,每次都会基于前一次的结果生成新的提示,直到这个智能体达到其目标。

需要注意的是:LLM 的核心功能就是接收文本并返回文本。就其本身而言,这并没有多大用处,除非它能够与文件系统、Web、数据库或 API 等服务进行交互。这就是人们开始构建让智能体能够挂钩(hook into)这些服务的方法的原因。
这是我和其他许多人曾陷入的最大思维模型陷阱。人们常常假设LLM本身能够访问服务。但实际上,LLM只是进行文本输入/文本输出。它是被动的。它不会主动连接任何东西。相反,公司(尤其是那些提供LLM即服务的公司)构建了额外的组件,充当代理,联系服务、运行循环、多次触发 LLM 等等。所有这些都是在后台(LLM API 背后)完成的。因此,很容易让人误以为 LLM 正在做这些事情。
如果你熟悉ChatGPT的研究或网络搜索功能,它们是在后端实现的。
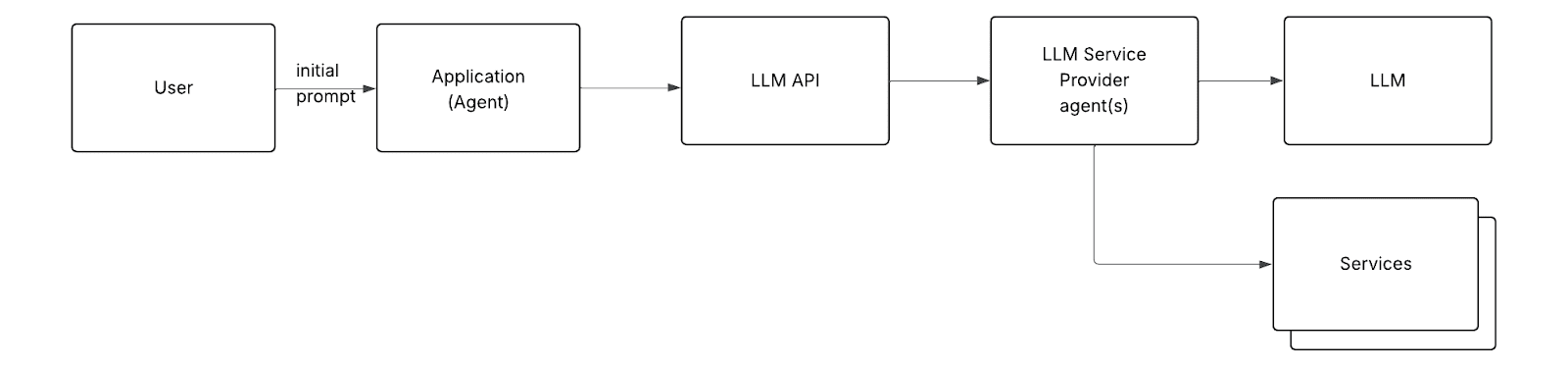
回到(在用户直接控制下的)智能体:与服务的集成被嵌入到智能体中。当智能体调用LLM时,它会在提示中包含类似以下的内容:“如果你想让我(智能体)访问资源/服务X,请使用以下响应格式。” 如果LLM返回格式符合该特定方式的响应,智能体会将其解释为一个动作(一个请求与服务交互),而不是字面文本。智能体执行它(通过访问该服务),并将执行结果发送回LLM。
由于本文重点关注用户或开发者控制下的智能体身份验证方面,我将在后续示意图中省略LLM服务提供商智能体的交互。它们作为黑箱运行,在架构、配置和身份验证方面不受我们控制。
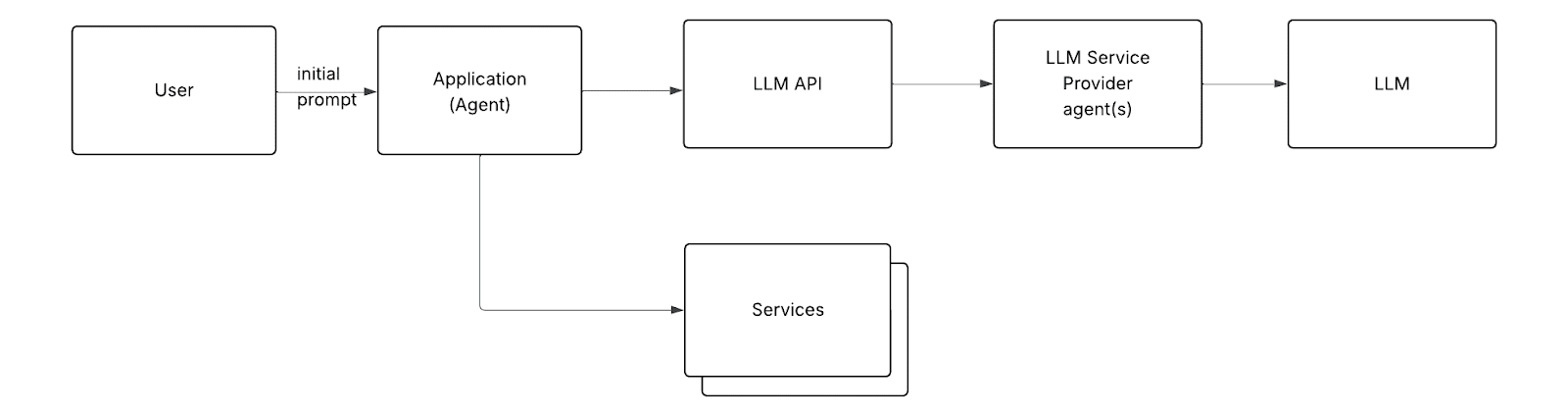
智能体与服务集成工作得很好,但这产生了一个问题:每个智能体开发者最终都要从头开始重新实现集成(或至少使用这些服务的SDK),并解决同样的问题(寻找合适语言的SDK、配置SDK、身份验证、通常是密钥管理、让LLM知道如何构建响应以便智能体知道是时候使用服务了,等等)。
这就是模型上下文协议(Model Context Protocol, MCP)的由来。它标准化了与服务集成的方式。想象一下,你的智能体需要访问Salesforce。它无需实现自定义逻辑,只需连接到一个已经知道如何与Salesforce通信的MCP服务器,就能立即获得读取潜在客户、联系人和帐户的能力。
智能体所需要做的就是告诉(嵌入在应用程序中的)MCP客户端MCP服务器的位置,指定位置和传输方式。MCP客户端处理大部分繁重工作:连接到MCP服务器、进行身份验证、发现其功能、将其暴露给智能体,并定义应如何将它们传达给LLM。
关键部分在这里。MCP协议定义了MCP服务器如何将其接口暴露给MCP客户端。这包括工具列表及其参数等细节。智能体使用MCP客户端检索此接口信息,将其(使用MCP中定义的方法)转换为文本,并发送给LLM。这让LLM知道智能体已通过MCP服务器获得了新的能力。
虽然解决集成不一致的问题很重要,但真正的突破是引入了一种标准方式来向LLM传达可用接口。
无论 MCP 服务器连接到哪个服务,它都能以一致的方式工作。这是一种经典的适配器模式,非常适合这种情况。(MCP 被广泛称为“人工智能应用的 USB-C”,这意味着你可以插入任何新的 MCP 服务器,它都能正常工作。)
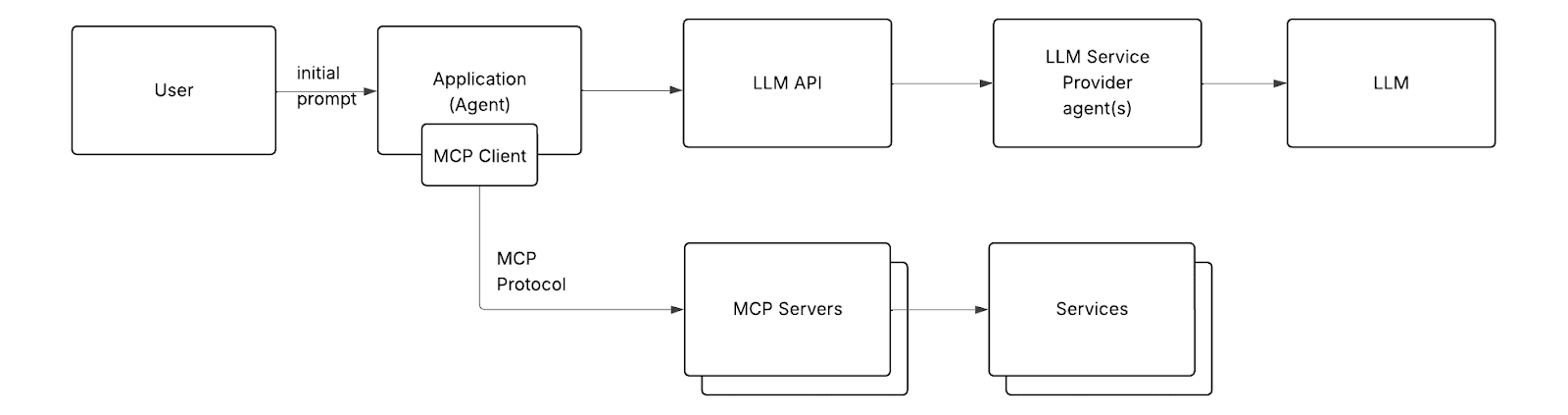
这种方法的另一个好处是,它将所有关注点(例如配置新的集成、确定集成可以执行的操作)从设计时(开发智能体时)转移到运行时。只需指向一个额外的 MCP 服务器,MCP 客户端就会自行处理剩下的事情。
到目前为止我所说的一切都有点简化。以下是一些可能的解释:
- LLM可能在本地运行,也可能在远程运行,在这种情况下,您可以绕过 API 层。
- 在LLM API和LLM之间(在LLM服务提供商端)可能存在提供额外功能的额外组件。
- 尽管MCP是标准化的,但你仍然需要特定语言的SDK来将其与用不同编程语言编写的智能体集成。
然而,忽略这些额外的细节,最后的示意图显示了许多人正在做的事情的重心所在。它使人们能够构建具有自身功能的智能体,轻松地与附加服务集成,而无需依赖像OpenAI这样的提供商在服务器端构建这些集成。
最后,这种模式允许一个智能体与其他智能体(也通过MCP)通信以构建更复杂的逻辑。因此,多智能体交互的完整图景可能如下所示:
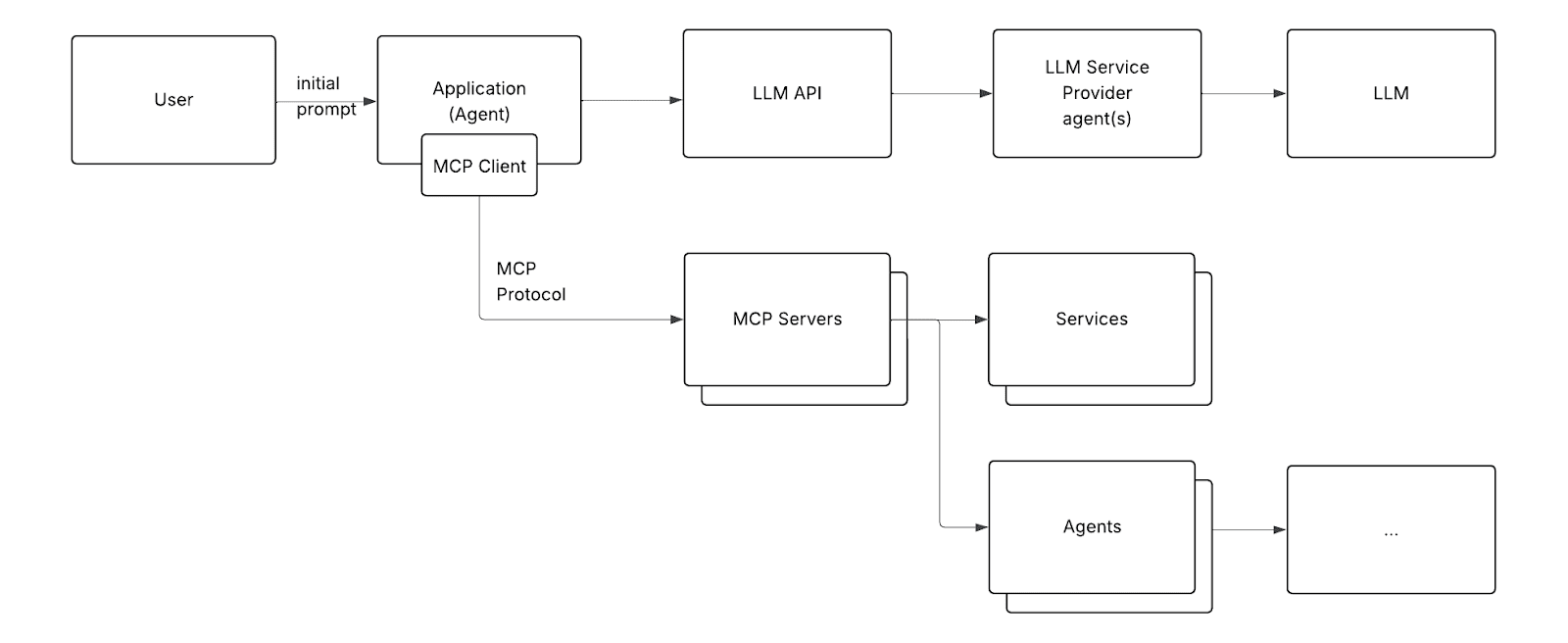
你可以与微服务进行类比。每个智能体都是一个微服务,可以与其他微服务或外部服务通信。
本节涵盖了智能体、LLM、MCP服务器和服务如何相互交互。接下来,我将介绍这些组件之间的身份验证(authentication)和授权(authorization),包括其工作原理以及已知的复杂性。
身份验证 (Authentication)
下图与上图相同,显示了三个信任边界(用虚线标记)。每次通信跨越这些边界时都需要进行身份验证。
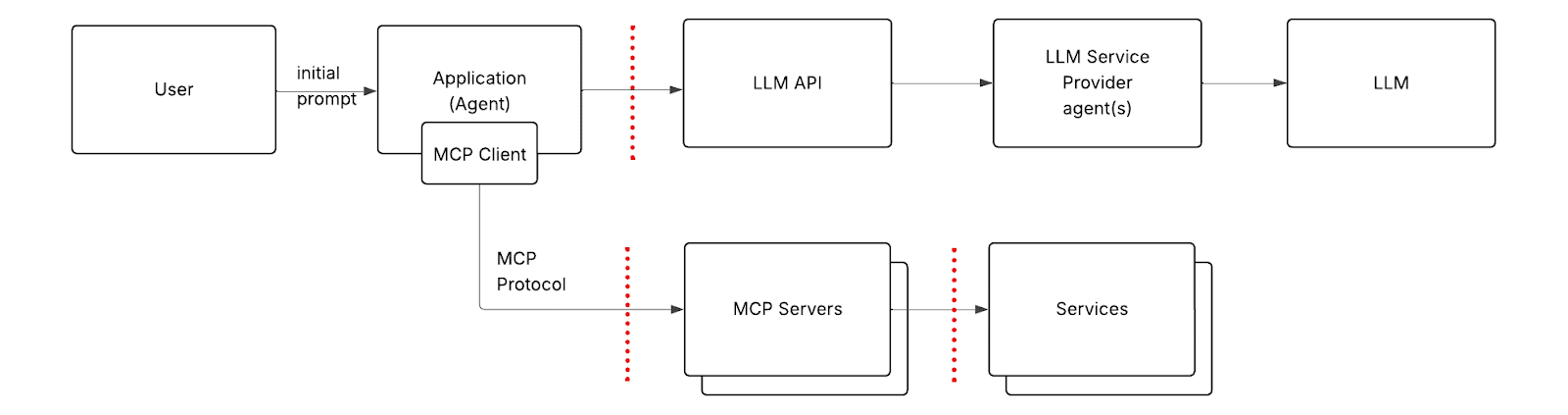
应用程序 → LLM API
这是特定于供应商的。也就是说,在大多数情况下,你会看到:
- OIDC 或 OAuth 2.0(OIDC基于此)。用户使用Google、Facebook等进行社交登录。他们通过 OAuth 流程获取相应的令牌。(在前端应用中管理这些(OAuth、OIDC)令牌就像一个潘多拉魔盒,里面充满了安全隐患。不同的应用程序对此的解决方案也不同。不过,这超出了本文的讨论范围,但值得一提。)
- API密钥。长期有效的密钥(long-lived secrets)仍然存在。您可以从 LLM 提供商处生成 API 密钥,将其粘贴到您的应用程序或代理中——就这样,您又开始为保护和管理该密钥而头疼了。
MCP服务器 → 服务
这是特定于技术的。虽然前一种情况很可能涉及基于 HTTP(S) 的身份验证协议,并且身份验证凭据很有可能最终出现在授权标头中,但 MCP 服务器到服务的信任边界具有更多变化。
如果 MCP 服务器与数据库通信,则需要使用数据库的身份验证方法。如果它与旧版本的 Kerberized 应用通信,则您处于 Kerberos 领域。
MCP客户端(嵌入到应用程序中)→ MCP服务器
在实践中,我检查过的大多数MCP服务器与MCP客户端运行在同一台机器上。MCP客户端启动MCP服务器进程,并通过标准输入输出(stdio)与其通信,根本没有任何身份验证。这是最简单的路径,但也是风险很高的路径,拉取未知的MCP服务器代码并在本地运行,通常具有与你的应用程序相同的权限。而且你计算机上的任何应用程序也可以调用这个MCP服务器(因为不需要身份验证)。
授权 (Authorization)
应用程序 → LLM
就目前而言,这里的授权是粗粒度的(coarse-grained)。你要么被授权使用LLM,要么没有。
MCP服务器 → 服务
鉴于这种交互可能涉及任何技术或协议,授权方案必然是技术特定性的。因此,不可能提供一个通用的描述。每种技术都实现自己的机制,这些机制在设计和复杂性上差异很大。
MCP客户端(嵌入到应用程序中)→ MCP服务器
这里我们有一个由 OAuth 授权服务器控制的细粒度授权。用户向授权服务器进行身份验证,授权服务器发放具有特定范围的访问令牌,以控制客户端可以执行的操作。
授权的复杂性
委托 (Delegation)
一旦你有一个调用链,例如,应用程序(带有MCP客户端)→ MCP服务器 → 服务,你会希望第二个组件(MCP服务器)代表第一个组件(应用程序)行事。
这是一个经典的委托问题。
在现代异构环境中(例如,当整个链都支持OAuth时),这个问题得到了一定程度的缓解。但当存在技术不匹配时,这个问题就无法解决。在这种情况下,下游服务会自行采取行动,而不是代表上游调用者。
我认为这种情况会持续下去。业界很可能会逐步摸索出代理到代理的委托机制。然而,一旦 MCP 服务器连接到外部服务,它将使用自己的身份,而不是原始用户或代理的身份。
有一些新的发展,如授权协商与授权协议(Grant Negotiation and Authorization Protocol, GNAP),试图在这一领域超越OAuth。但我们还得拭目以待它是否能获得广泛采用。
动态权限 (Dynamic Permissions)
过去,软件可以说是静态的;你事先知道它应该做什么。它只被授予必要的权限,仅此而已,遵循最小权限原则。对于依赖LLM来决定下一步行动的智能体来说,情况正变得复杂。
示例:假设你的公司服务于国际市场,你决定编写一个智能体将所有客户支持工单翻译成英语。最初,您认为工单系统的只读权限就足够了。但实际上,您还需要写入权限才能将翻译结果上传回去。然后智能体发现大的附件存储在S3存储桶中。现在它需要对该存储桶的读/写权限。后来,它遇到一个被锁定且无法修改的工单。智能体决定创建一个副本,现在它需要创建新工单的权限。
过去,开发者会在开发期间识别这些需求,并协调相应地提升权限。现在,同样的用例由智能体动态发现和处理。你拥有的智能体越多,它们越智能,它们就越会挑战边界。关于如何处理这个问题,目前还没有明确的答案。
用户与机器身份的混合 (Blend of User and Machine Identity)
想象以下场景。你有一个与HR系统交互的智能体。你是一个授权用户,并要求查询员工数量。智能体尝试计数,但发现一些记录缺少员工/承包商状态。智能体找到文档说明缺少状态意味着是员工。智能体(通过MCP)尝试用空字符串查询,但HR系统不允许。于是智能体决定将空状态字段更新为“employee”,结果这是错误的,因为文档已过时。注意一个简单的只读操作如何变成了破坏性的更新。
现在问问自己:谁应该为这个变更负责?用户还是智能体?
智能体应该使用用户的权限来执行操作(因为用户被允许进行此类更改),还是应该在其自身、更受限的权限集下行动(这可能会完全阻止更改)?当采取此类行动时,应该使用谁的身份?
在这种情况下,感觉上应该是智能体的身份。但很容易想出一个用例,你会说应该是用户的身份。我们如何创建两者的混合,授予足够的权限以允许必要的操作,同时限制不应做的事情,并保持用户和智能体都承担责任?这是一个全新的问题,值得大家思考...
总结
智能体AI可能让人感觉熟悉;许多关于身份验证和授权的挑战似乎与我们传统全栈应用中见过的类似。然而,由LLM驱动的智能体将我们推入了新的领域,关于架构、集成和安全性的旧有假设开始瓦解。随着我们构建更强大、更自主的系统,身份验证和授权不仅仅是实现细节;它们成为核心构建块,塑造了什么是可能的以及什么是安全的。这片领域仍在演变,标准仍在巩固,最佳实践仍在被发现。
文章来源:https://cloudsecurityalliance.org/blog/2025/08/18/the-definitive-catch-up-guide-to-agentic-ai-authentication
审校:茆正华,CSA大中华区专家

手机:19925407556
邮箱:info@c-csa.cn
 雷池WAF
雷池WAF 安恒信息
安恒信息